Prédiction
Les registres nationaux et les données de grandes cohortes permettent aux médecins d’apprécier un niveau de risque d’événement clinique au niveau populationnel. Il est plus difficile de fournir un pronostic à l’échelle individuelle du fait de la multiplicité des facteurs de risque. Aussi, les scores pronostiques d’évènements cliniques sont devenus des outils populaires dans le cadre des maladies chroniques pouvant aider à la mise en place d’une médecine 4P (prédictive, personnalisée, préventive et participative) et facilitant la prise de décision médicale partagée entre médecins et patients.
Au sein de l’équipe de recherche SPHERE, nous avons développé et validé plusieurs scores pronostiques dans différents contextes cliniques :
- Le KTFS est un score pronostique du retour en dialyse des patients transplantés rénaux calculable à 1 an post-transplantation
Lien vers KTFS Lire la publication - Le 1-RRS est un score pronostique de la mortalité chez les patients transplantés rénaux et calculable à 1 an post-transplantation
Lien vers 1-RRS Lire la publication
- Le 1-RBI est un score diagnostique de l’anormalité histologique d’une biopsie rénale à 1 an post-transplantation
Lien vers 1-RBI Lire la publication
- Le SMILE est un score prédictif d’invalidités résiduelles à 6 mois post-rechute chez des patients atteints d’une sclérose en plaque
Lien vers SMILE Lire la publication
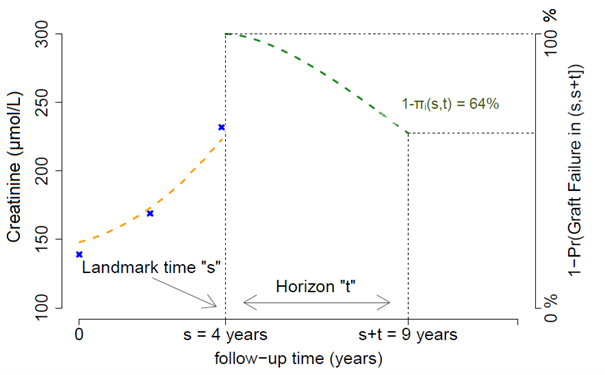
- Le DynPG est score pronostique dynamique de l’échec de greffe rénale qui peut être mis à jour au cours du suivi du patient transplanté
Lien vers DynPG Lire la publication
- Le DynHFH est score pronostique dynamique de l'hospitalisation pour insuffisance cardiaque chez les patients diabétiques
Lien vers DynHFH Lire la publication
L’unité SPHERE porte des travaux de recherche sur les problèmes méthodologiques relatifs à la modélisation du pronostic. A titre d’exemples :
- Le Borgne et al. ont proposé les courbes ROC dépendantes du temps standardisées et pondérées pour évaluer les capacités discriminantes d’un marqueur pronostique en présence de facteurs de confusion.
Lire la publication
- Asar et al. ont utilisé une approche par modélisation conjointes robustes pour données longitudinales et données de survie afin d’améliorer la précision des prédictions dynamiques en présence de valeurs longitudinales extrêmes.
Lire la publication
- Fournier et al. ont proposé d’évaluer les performances prédictives globales de prédictions dynamiques à partir de courbes de R2.
Lire la publication
Causalité
Prédiction et causalité ont souvent été considérées comme deux champs distincts. Pourtant, prédire est la première étape de la modélisation en inférence causale. Pour des scores de propension, il est nécessaire de prédire l’exposition, pour les méthodes dites de « G-computation », il est nécessaire de prédire le résultat. Ces deux approches utilisent des caractéristiques des patients. Des travaux méthodologiques sur l’inférence causale ont été menées au sein de SPHERE :
- Lenain et al. ont utilisé des scores de propension dépendant du temps pour apprécier le bénéfice d’une greffe de rein comparativement au fait de rester en dialyse en attente d’une greffe.
Lire la publication
- Chatton et al. ont comparé plusieurs approches méthodologiques (g-computation, inverse probability of treatment weighting, full matching, targeted maximum likelihood estimator) ayant pour objectif de tenir compte des biais de confusion en inférence causale.
Lire la publication
- Foucher et al. ont évalué l’effet causal d’une greffe de rein pré-emptive à partir de donneurs décédés en utilisant un modèle de Cox cause-spécifique pondéré par scores de propension.
Lire la publication
Nous poursuivrons nos travaux de recherche sur la causalité avec de nouvelles approches issues des techniques de « Machine Learning » quand l’exposition/ le traitement est dépendant du temps ou pour des « outcomes » de type « time-to-event ».
Dans le cadre de la modélisation de données longitudinales rapportées par les patients ou de syndromes psychiatriques, nous souhaitons étudier les problèmes méthodologiques liés à la détermination de relations causales entre de nombreux agents d’un système. En effet, les interdépendances entre les items de données rapportées par les patients peuvent être étudiées via le paradigme de la « network psychometrics ».
Une étude sur le réseau des relations entre les items d’un questionnaire de qualité est en cours. Via les modèles structuraux, de futurs travaux sur l’étude des relations causales conjointes croisées, de médiations, ou rémanentes sur des données longitudinales de multiples syndromes psychiatriques sont envisagés.